2025春 2024春 2023春 2022春 2021春 课程号:DS300101
- 课程难度:中等
- 作业多少:中等
- 给分好坏:一般
- 收获大小:一般
| 选课类别:计划内与自由选修 | 教学类型:理论实验课 |
| 课程类别:本科计划内课程 | 开课单位:人工智能与数据科学学院 |
| 课程层次:专业核心 | 学分:3.0 |
课程内容与教学
刘淇老师的《数据分析及实践》课程涵盖了数据处理、统计方法、机器学习和深度学习等主题。尽管主题广泛,但课程设置更多作为导论性质,每个领域的讲解较为基础。课上存在频繁的小测,用于考勤和鼓励课中参与,但具体的教学内容与实验任务并不直接相关。
实验与作业
本课有五次实验和一次文献调研。实验涵盖了Python编程入门、网页爬虫和数据分析等内容。实验报告须自行撰写,且缺乏明确的评分标准和即时反馈。许多学生认为实验报告的评分较为主观,需展现个人思考和尝试,报告的完成程度对总评分有显著影响。文献调研需要深入研究并撰写报告,也在总评分中占重要权重。
考试及给分
期末考试主要覆盖课上讲授的PPT内容,形成了一种高压的背书模式,考试范围极广,考试安排紧密且不提供往年试卷或样卷。部分学生反映考试出题模式不尽合理,给分则因不公布具体标准而备受争议。尽管如此,一些学生通过勤勉的实验和报告工作获得了满意的成绩。
学生反馈
评价中对课程的看法不一,正面评价主要集中在通过课程学习到的实用技能,如Python和数据分析技术,对未来学习有潜在积极作用。反面意见则集中在课程内容与实验的脱节、小测频繁、实验评分不透明以及考试要求不明确上。特别是对于大二乃至未具备较强编程基础的学生而言,课程挑战较大,需自学搭配课外资源完成任务。
综合建议
选课前建议提前学习Python及相关数据分析库(如pandas和sklearn),并提升自学能力以应对实验的复杂性。如果希望丰富数据分析实践经验且能够投入较多精力,该课程仍然值得考虑。对于看重考前准备和平常反馈的学生,需慎重选择。
- 课程难度:中等
- 作业多少:中等
- 给分好坏:一般
- 收获大小:一般
- 难度:中等
- 作业:中等
- 给分:一般
- 收获:一般
2025.8.31
千呼万唤始出来,拖了两个多月终于出分了,这效率无敌了👍。
选课须知:
- 教务系统上的考核方式为大作业,但从 2024 春开始,考核变成期末闭卷考试(平时 : 实验 : 期末 = 2 : 3 : 5);
- 该课程与 CS4023 数据科学导论 以及 NNM2012 新媒体大数据分析 的学分不可重复认定(课程替代库里没有,但是 PPT 上这么写的);
- 考勤较多,点名不计其数,小测大概有 4 次,正确率会影响得分,与期末考试内容强相关;
- 出分极其缓慢,不建议大四的同学选课。
2025 春实验:约 3 周一个实验,没有反馈
- Python 编程练习:只涉及基本的语法,那我缺的 Matplotlib、Pandas、Sklearn 这块谁给我补啊;
- 网页爬虫:Python 爬取 Nature 期刊数据并结构化存储;
- 数据分析:基于 PISA 2018 数据集,进行探索性分析、可视化分析和特征关系分析;
- 关联规则发掘:基于 PISA 2018 数据集,挖掘部分问卷属性的频繁项集与关联规则;
- 特征预测:基于 PISA 2018 数据集子集,对部分属性进行分类预测,并尝试调用大语言模型进行辅助分析。
一些有用的东西:
- 爵士毫克:UCB Data100: Principles and Techniques of Data Science;
- 手敲试卷:2025春 数据分析及实践 期末试卷;
- 偷的回忆:2024春 数据分析及实践 期末部分回忆;
- 分类:金融风控贷款违约预测;
- 回归:二手车交易价格预测;
- 竞赛:Baseline & Topline 分享。
为什么这门课会出现“课堂与实验严重脱节”的问题?这门课其实是在原本的《数据科学导论》基础上,增添了一些实践性的数据分析实验,但是课堂仍停留在导论层面,并没有随着实验而进行改革。于是,知识性的“数据分析”部分,和工具性的“数据实践”部分,就这样强硬拼凑在一起,摇身一变,成了今日所谓的《数据分析及实践》。不过这种授课方式最好水了,所以我估计老师也懒得改。

本来想对这门课写一些系统性的分析和改革建议,不过鉴于嗯嗯擅长脱离群众、忽视实际的尿性,我觉得写了意义并不大,所以懒得写了。下面的内容全是“梦到哪说到哪”的,不保证真实性正确性合理性,大家权当看个乐子。
守序:广而不杂,深而不晦;条理井然,言之有序。
混乱:空而不实,乱而无章;逻辑混乱,漏洞百出。
善良:作业精研,指导详尽;考勤宽厚,待遇从容。
邪恶:实验放养,反馈无期;点名频仍,小测繁琐。
这门课是守序善良还是混乱邪恶大家心知肚明。上课也没啥人听,刚开学有一次我玩手机间隙抬头看了一圈,大部分人都低着头,有人荒野大乱斗、有人恶搞之家、有人潜伏、有人 Switch;小测没几个人会,直接零帧起手,开始怒斥群臣……课程内容主打一个点到为止广撒网,我打赌上完这门课的人知道什么是独热编码,但是没多少人知道这是什么:
from sklearn.preprocessing import OneHotEncoder
def one_hot_enc(df, f):
x = df[[f]].fillna('missing')
enc = OneHotEncoder(handle_unknown='ignore', sparse_output=False)
one_hot_array = enc.fit_transform(x)
colnames = enc.get_feature_names_out([f])
df[colnames] = one_hot_array
return df实验不给反馈,考试不给范围,说要给参考公式也没给,出分也奇慢无比。还有,哪个神人想出来的考核从大作业改成考试的?虽然大作业可能会面临下图问题,但是通过一些恶心的手段来强行增加区分度的考试能强到哪去?用这些时间去打打比赛不比无脑背诵 PPT 上那些无聊的八股有用?

祖传的课程主页,没更新过的 Slides,神秘的阅读链接:

又红又专,理实交融,政治也是数据科学基础!

中英杂糅,混合双打:


不搞点图层遮挡,你怎么知道你看的是 PDF:

遍地贴满了失效的链接:
莫名其妙、夹带私货、大肆铺张的参考文献:


打好数理基础!直接对标高考!


简单的东西我要展开讲:

复杂的东西你去自己猜:
AI 屋及乌,大 AI 无疆:


对不起我错了,要不你还是让 AI 算吧:

三过家门而不入,三乘数据而不改:

Java 取代 Python 势在必得!

杰森文档:
张冠李戴:

活算法?死算法!
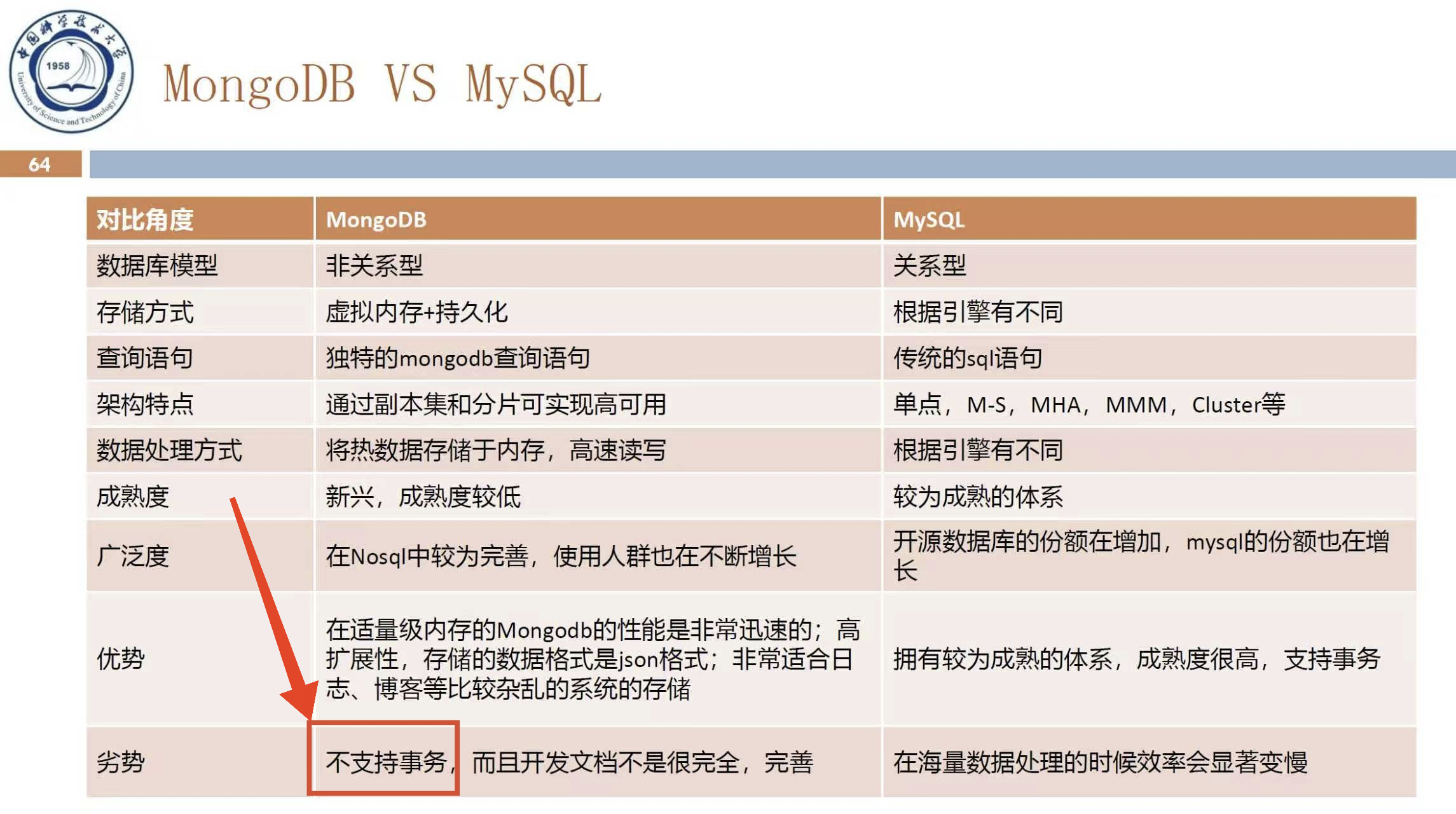
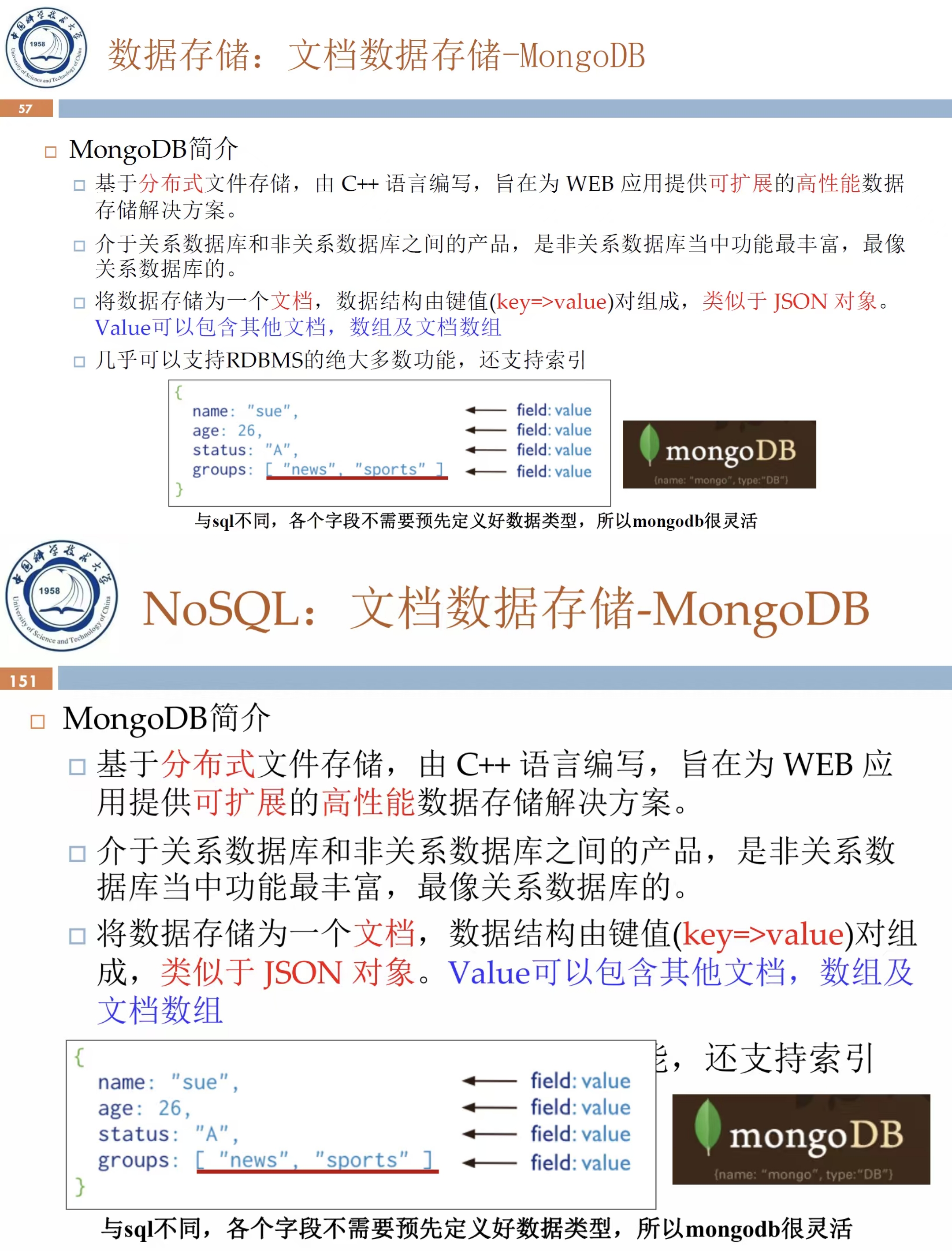
MongoDB 是 NoSQL,PPT 是 NoUpdate:
我 TLS 肯定上不了台面:

有人托梦给你的答案???
“女生不用交”的“特权”小测,喜欢老师的恶趣味吗:
PPT 找不同!数据分析及实践 V.S. 数据库系统概论!




2025.6.19
没有往年卷是吧,跟你爆了😡😡😡
2025 春 数据分析及实践 期末考试
一、单选题(共 30 分)
1. 网络爬虫不包括( )
A. 载入过程 B. 解析过程 C. 检索过程 D. 存储过程
2. 某时间段抽取 10 位顾客的购买记录:购买物品 A、B、C 的分别有 2、3、5 人。求信息熵( )
A. 5.06 B. 18.36 C. 1.03 D. 1.49
3. 哪一种数据变换方法把数据缩放到 [0, 1] 区间( )
A. Z - score 标准化 B. 最小 - 最大规范化 C. 独热编码 D. 数据离散化
4. 关于假设检验,下列说法正确的是( )
A. 假设检验的目的是接受原假设。
B. 第一类错误指拒绝了错误的原假设。
C. 假设检验中,犯第一类错误的错误率即为置信度。
D. 大数据分析不涉及假设检验。
5. 下列哪项不属于 NoSQL(数据库)的特点( )
A. 数据模型简单 B. 数据有高度一致性 C. 灵活性强 D. 高性能
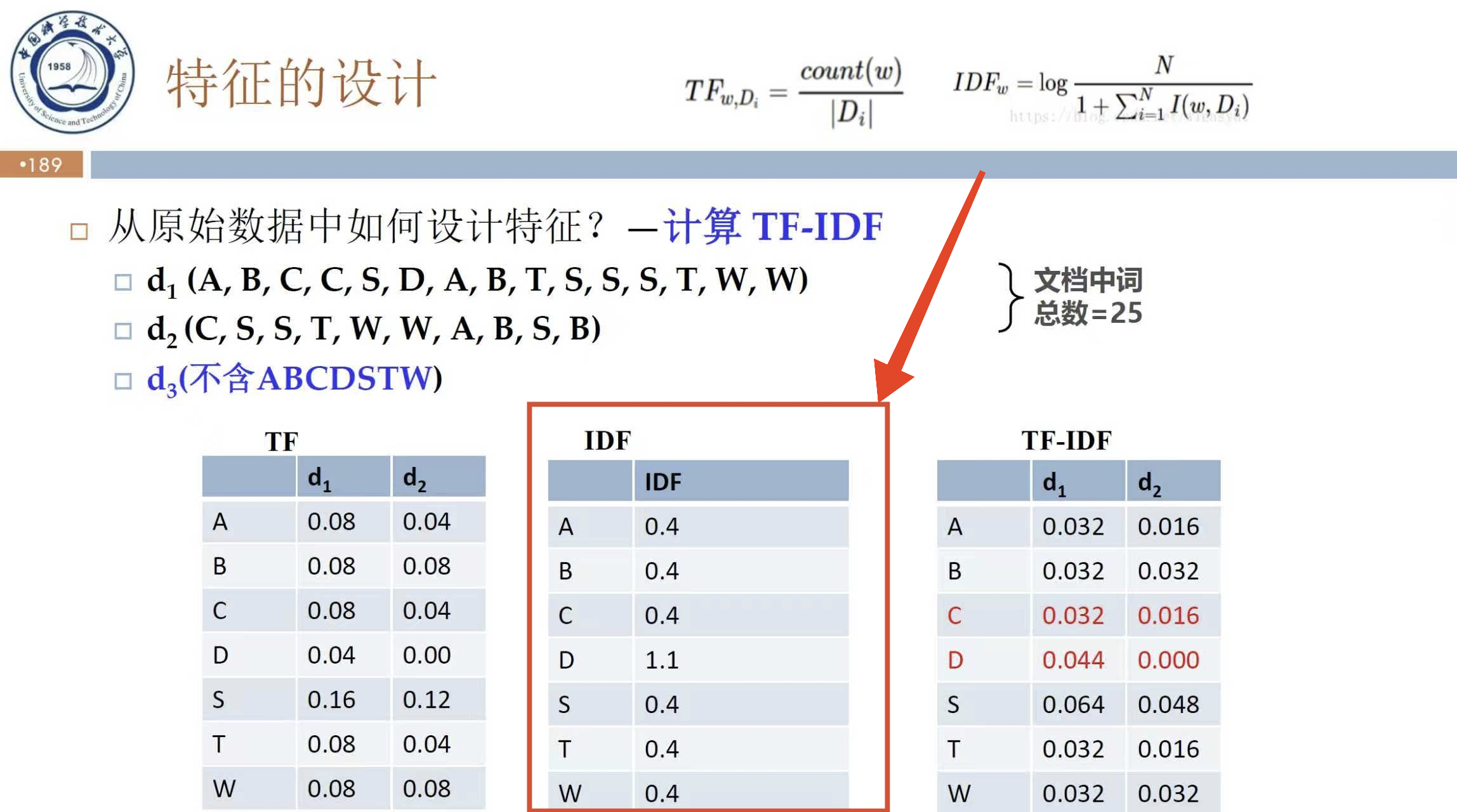
6. 关于 TF - IDF 说法正确的是( )
A. TF 是逆文档频率。
B. IDF 用于衡量词语在单个文档中的重要性。
C. TF - IDF 可用于提取文档关键词。
D. TF - IDF 算法复杂,效率低。
7. 关于数据分布,说法错误的是( )
A. 集中趋势反映了一组数据中心点位置,以及该组数据向中间靠拢或聚集水平。变异系数是常用指标。
B. 数据离散程度增大,集中趋势的测度值对该组数据的代表性越差,反之亦然。
C. 在数值型数据中,刻画数据围绕其中心位置附近分布数字特征时,常用方差和标准差。
D. 若极差或四分位差较大,建模时需考虑数据是否有长尾现象。
8. 某医院进行病症诊断,某病诊断出 120 例病例。后续确诊过程中,发现只有 80 例真正患病,其余 40 例是误诊(假阳性),则该诊断方法的正确率(Precision)为( );假设样本中仍有 120 例未被诊断(漏诊,假阴性),则该诊断方法的查全率(Recall)为( )
A. 66.7% 40% B. 33.3% 60% C. 66.7% 60% D. 33.3% 40%
9. 哪些指标属于不确定性时序预测评价指标( )
A. CRPS B. MSE C. RMSE D. MAE
10. 哪个数据挖掘算法是最为代表的符号主义流派( )
A. 感知机 B. 支持向量机 C. 决策树 D. 关联规则
二、简答题(共 20 分)
1. 请简述 3 种数据预处理方法,并说明为什么要进行数据预处理。
2. 请简述特征工程的意义以及主要流程(步骤)。
3. 请简述如何进行假设检验,并说明假设检验和参数估计的区别。
4. 请简述 ROC 的绘制方法,并说明当 AUC 为 0.5 和 1 时分别代表什么。
5. 请简述 K 近邻(KNN)算法的基本原理,并说明其为什么被称为“非参数方法”。
三、计算题(共 50 分)
1. 给定两个 5 维数据点 \(x_1=(1\ 1\ 0\ 1\ 0)\),\(x_2=(0\ 1\ 1\ 0\ 1)\),请依次计算 Jaccard 相似度、Cosine 相似度、Euclidean 距离、Pearson Correlation 值。
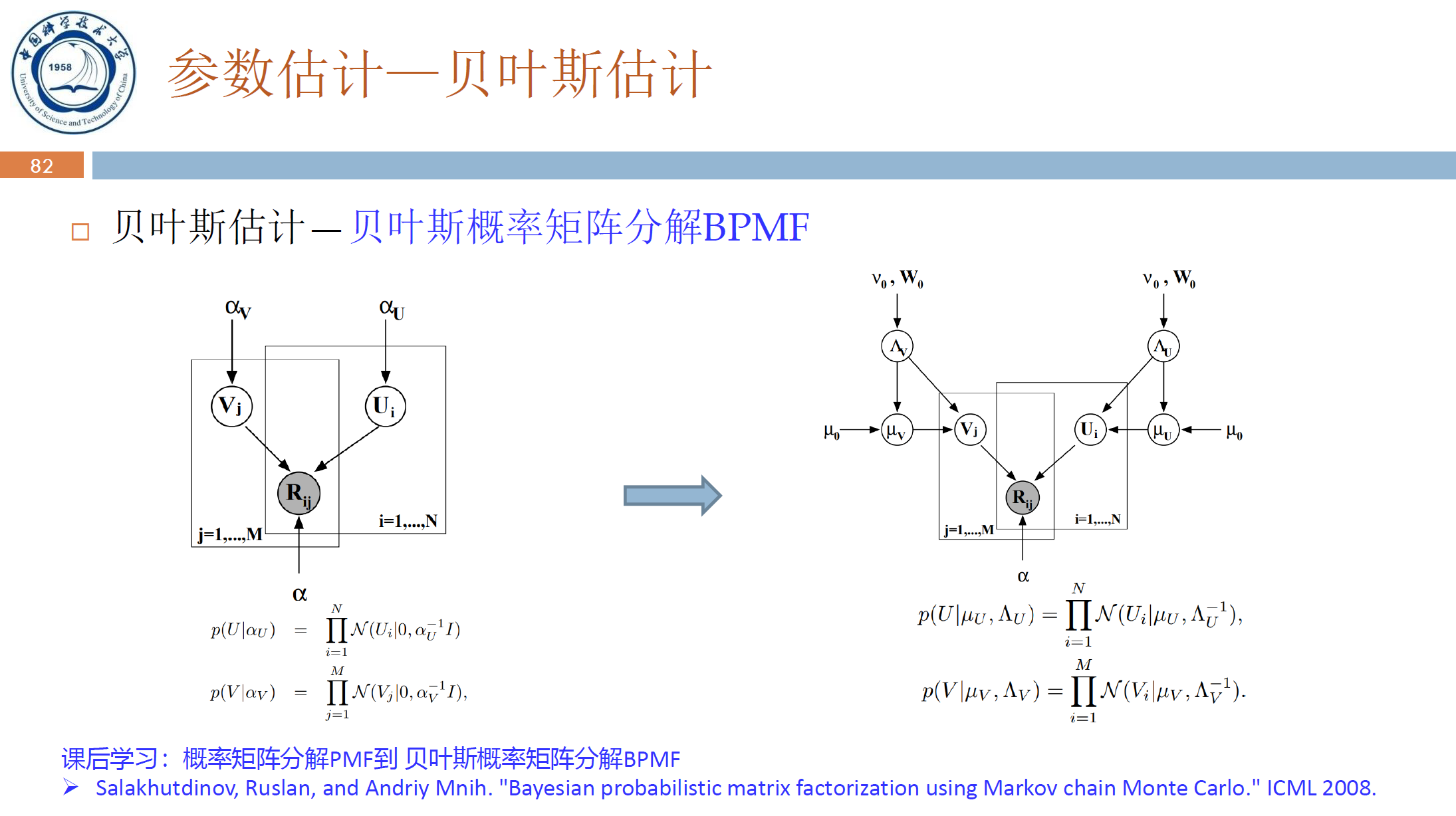
2. 概率矩阵分解方法可用于预测用户对未评分项目的评分。对每个用户 \(i\) 和每个项目 \(j\) 都可以通过潜在因子矩阵 \(U\) 与 \(V\) 表示,用户项目评分矩阵 \(R\) 可以近似建模为 \(R_{ij}\approx U_i^TV_j\),如图所示。
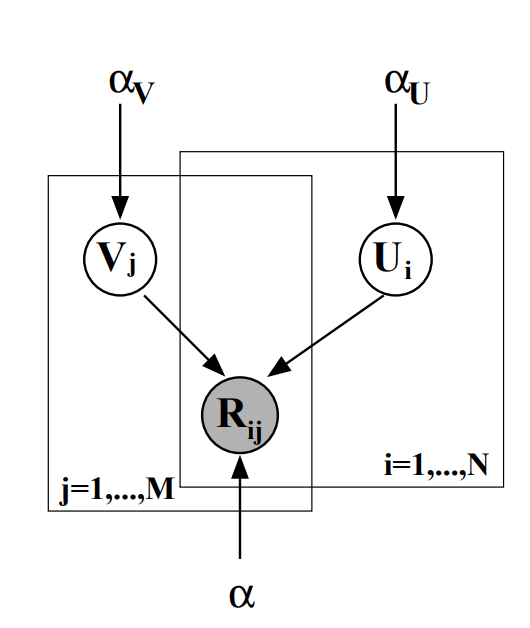
假设 \(R_{ij}\) 服从高斯分布,方差为 \(\sigma^2\),每个评分相互独立。用户潜在因子 \(U_i\) 和项目潜在因子 \(V_j\) 服从均值为 0、方差分别为 \(\sigma_U^2\) 和 \(\sigma_V^2\) 的高斯分布。用最大后验概率估计参数 \(U\) 和 \(V\),即最大化 \(p(U,\ V|R,\ \sigma^2,\ \sigma_U^2,\ \sigma_V^2)\),写出优化目标公式即可,不用求导计算。
3. 以下是某商店的交易清单。请使用 Apriori 算法,以支持值阈值 33.34%、置信度阈值 60%,详细记录算法的执行过程。列出每次数据库扫描的候选项集和频繁项集,列出所有最终的频繁项集,生成所有的关联规则,标出其中的强关联规则,并且按照置信度排序。
| 交易 ID | 物品 |
| T1 | 中性笔、笔记本、荧光笔 |
| T2 | 中性笔、笔记本 |
| T3 | 中性笔、矿泉水、巧克力 |
| T4 | 巧克力、矿泉水 |
| T5 | 巧克力、荧光笔 |
| T6 | 中性笔、矿泉水、巧克力 |
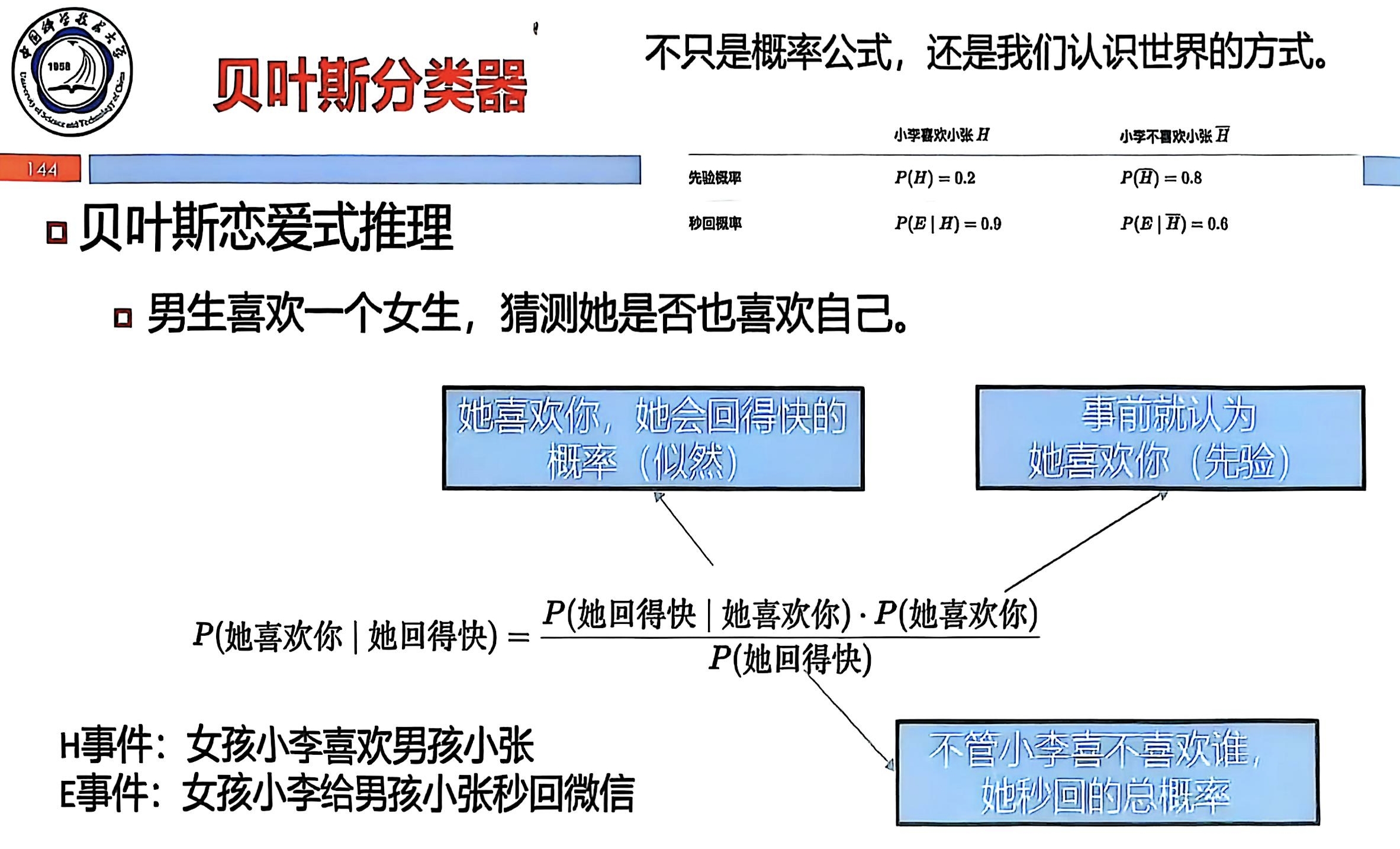
4. 滑雪。两种属性:天气(晴天、雨天、雪天)和降雪量(≥ 50、< 50)。小明 8 天的训练集如下:
| 天气 | 晴天 | 雨天 | 雨天 | 雪天 | 雪天 | 晴天 | 雪天 | 雨天 |
| 降雪 | < 50 | < 50 | ≥ 50 | ≥ 50 | < 50 | ≥ 50 | ≥ 50 | < 50 |
| 滑雪 | 否 | 否 | 否 | 是 | 否 | 是 | 是 | 是 |
(1) 计算训练集中“滑雪=是”和“滑雪=否”的先验概率;
(2) 计算每个属性在两类别下的条件分布;
(3) 请你帮助小明做出决策,使用贝叶斯分类器决策。
| 序号 | 天气 | 降雪 |
| A | 晴天 | ≥ 50 |
| B | 雨天 | < 50 |
| C | 雪天 | < 50 |
5. 某电网过去 6 小时的负荷(单位:MW)如下图:
| 小时 | 1 | 2 | 3 | 4 | 5 | 6 |
| 负荷 | 500 | 504 | 509 | 515 | 520 | 528 |
使用 ARIMA(1, 2, 1) 预测第 7 个小时的负荷。其中,AR(1) 系数为 \(\Phi_1=0.5\),MA(1) 系数为 \(\theta_1 = -0.4\),初始残差 \(\epsilon_1=0\),\(\epsilon_2=0\),\(\epsilon_3=0\)。
2025.6.18
⚡⚡PPT 看得我不知天地为何物了⚡⚡
有没有前辈说说考试题型是什么😭😭😭
真的复习不下去了😭😭😭
- 课程难度:中等
- 作业多少:很少
- 给分好坏:一般
- 收获大小:没有
- 难度:中等
- 作业:很少
- 给分:一般
- 收获:没有
难蚌,课程实验和上课正交,期末考试说只要ppt出现过就要考,600页ppt,把我当神了吗🤔考试时间也是逆天,第二天就是量物,教务处属于是把我当日本人整😨😥😱
- 课程难度:困难
- 作业多少:很多
- 给分好坏:一般
- 收获大小:一般
- 难度:困难
- 作业:很多
- 给分:一般
- 收获:一般
哈基咪南北绿多,阿西噶阿西,阿西哈雅酷奶农,哈基咪哈基,哈基咪摸南北绿多,阿西噶哈雅酷奶农,哈基咪曼波亚不亚不有待有待哦吗吉利曼波,哈基咪摸南北绿多,阿西嘎哈雅酷奶农,吗吉利哇呀曼波,哈基咪哈基咪我的贝绿多,亚不亚不有待有待啊曼波啊吗吉利,哈基咪摸南北绿多,哈基咪摸南北绿多,哈基咪摸南北绿曼波
- 课程难度:中等
- 作业多少:很多
- 给分好坏:一般
- 收获大小:没有
- 难度:中等
- 作业:很多
- 给分:一般
- 收获:没有
要是可以打零颗星就好了
完全是一坨屎
一坨屎
我说这课是一坨屎!!!!
实验五个,从没学过python的完全不友好
反正没有一行代码是我写的
考试既没重点也没往年题助教啥信息也不给
考点完全猜不透,根本是一坨
谁选谁倒霉吧我只能说
考试安排还很密集PPT700页傻逼来的
我说这课是傻逼来的!
- 课程难度:中等
- 作业多少:中等
- 给分好坏:一般
- 收获大小:一般
- 难度:中等
- 作业:中等
- 给分:一般
- 收获:一般
虽然作为妮可信智的学生,我已经习惯主要面向实验进行学习了。但是第一次碰到实验和上课内容完全正交的课程还是有一点难绷😇
考完试更:
沉默了,说不出话了,被震撼到了。
我们aids确实是这样的,代码作业是和上课正交的,考试是包含所有ppt内容的,公式是不给的,概念是要考的(甚至有的东西ppt上都没有/矛盾的)。
PPT上数据预处理那一章写了四部分,考试只问三个,剩下一个是和我的复习一样完全不重要吗?
当然,我能理解老师的苦衷,如果给出考试大纲,凭aids的卷度一定能把平均分干到80+甚至90+;实际上老师说这门课改成考试就是不希望大家再卷最后的报告这种东西。不过思考一下这个问题:对于一个aids的学生来说,如果卷是不可避免的,那么是熬夜背诵特征工程的定义和流程更有用,还是刷baseline之类的东西?
- 课程难度:困难
- 作业多少:中等
- 给分好坏:一般
- 收获大小:一般
- 难度:困难
- 作业:中等
- 给分:一般
- 收获:一般
没有样卷,没有往年题,没有考纲,只有加起来七百多页的ppt,我不知道怎么赢
我也是不懂了,死活不愿意说公式会给到什么程度是干什么???
终于知道为什么不肯说公式会给到什么程度了,因为任何公式都不给
- 课程难度:困难
- 作业多少:很多
- 给分好坏:一般
- 收获大小:没有
- 难度:困难
- 作业:很多
- 给分:一般
- 收获:没有
0分打给这门课,也打给我自己
为什么开学的时候选了这门课
- 课程难度:简单
- 作业多少:很少
- 给分好坏:杀手
- 收获大小:一般
- 难度:简单
- 作业:很少
- 给分:杀手
- 收获:一般
选择简答题全考概念还不开卷。不如直接改名背书课算了
哪个nt提出这门课要从大作业改成考试的
- 课程难度:中等
- 作业多少:很多
- 给分好坏:一般
- 收获大小:一般
- 难度:中等
- 作业:很多
- 给分:一般
- 收获:一般
终于出分了……结果勉强还行吧,附上我的复习资料造福后世,筑波不会重修这门课了。
怎么还不出分怎么还不出分我的成绩呢成绩呢成绩呢
作为一个必修的ds人,不得不上了,想说几句:
1.这门课实验和上课考试完全正交
2.基本上每节课都要点名和小测,小测成绩计入总评
3.一共五个实验,实验内容并不容易,只能对着gpt 拟合,但是时间给的很紧迫,一个接着一个,也不知道实验的评分标准(到现在仍未得知自己实验分数)非常难顶
4.考试无样卷无考纲,只有700多面的ppt,所有都是范围,说会给公式,我考完怎么一个公式也没看到呢???选择题简答题全都是概念题,为什么还在闭卷呢???为什么不能给个样卷或者往年卷呢???
总而言之,这是一门 每节课小测点名,实验任务巨大,到现在教务系统上还写着“大作业”但是要对着ppt狂背所有内容考试还是记不住的神秘课程。
- 课程难度:简单
- 作业多少:中等
- 给分好坏:一般
- 收获大小:没有
- 难度:简单
- 作业:中等
- 给分:一般
- 收获:没有
哈姆,哈姆,哈姆,哈姆的哈的贝哈姆哈姆的的哈贝贝,哈姆的哈的贝哈姆哈姆的哈贝贝,哈姆,哈姆,古莫德那德米列洛姆,古莫德那德米列洛玛,古莫德那德米列洛玛,阿珂么德哈马迪,阿珂么德哈马迪,哈姆,哈姆,哈姆
- 课程难度:中等
- 作业多少:中等
- 给分好坏:一般
- 收获大小:一般
- 难度:中等
- 作业:中等
- 给分:一般
- 收获:一般
这门课是被遗忘了吗 怎么还不处分 。考虑到ds高手们和ai卷怪们的存在,对最后的总评也不抱太大期望了
ai人选修 ,说实话这学期的各种课真的非常消磨人的学习热情。这门课上课授课内容覆盖面很广,但讲的都不深入,自己看PPT完全可以。后半学期每节课都有零帧起手的点名回答问题…(苦了刘翔同学)考试更是绷不住,选择简答考成文科题了,最后一道大题ARIMA的计算 随机过程b都不做考试要求的玩意结果出在了数据分析 ,凭着很模糊的记忆胡乱写几笔了事。事实就是几百页的ppt,每一页的每一行的每一个知识点都有可能出在期末试卷里 。体验总之很不好
- 课程难度:中等
- 作业多少:中等
- 给分好坏:一般
- 收获大小:一般
- 难度:中等
- 作业:中等
- 给分:一般
- 收获:一般
那还是比量子物理阳间
6.18下午计组
6.18晚上数据库大作业答辩
6.19下午这个
6.20下午量子物理
人形乱序超标量处理器√
全考完再来评
- 课程难度:困难
- 作业多少:很多
- 给分好坏:超好
- 收获大小:一般
- 难度:困难
- 作业:很多
- 给分:超好
- 收获:一般
出分真够慢的…给我的分挺好的,我的实验都是东拼西凑写的,还有两三个实验没跑出最终结果,但是小测全勤,期末考试因为被上届学姐打了预防针所以有心理准备,考得应该还行,这样能给我3.7我已经知足了。课是一坨,实验和课堂完全正交,上课还喜欢提问和小测,建议是好好准备期末考试,什么偏难怪的概念都看一看。
- 课程难度:简单
- 作业多少:很少
- 给分好坏:一般
- 收获大小:很多
- 难度:简单
- 作业:很少
- 给分:一般
- 收获:很多
这门课当然是很有用的。我个人感觉收获很多。
但是没有往年卷太伤了。700多页PPT,几十个算法、模型。期末周结束后复盘,发现除了离散数学和计嵌,就这门课花时间最多。
不给往年卷,不给考试范围的意义在哪里?逼着学生把700-800页PPT背完吗?这种应用性质的课程,是把知识背下来重要,还是学懂会用重要呢?
不过pksq有大佬发了往年卷,学弟学妹们应该会好过很多吧